In a recent blog post, we discussed what has to happen before machine learning in digital olfaction takes place. Today, we’ll outline how machine learning, which is what we do at Aryballe, actually works in digital olfaction. Notably, we run models on the data acquired during the learning phase to deliver odor analysis – from detecting an unknown smell, to predicting the time to an event based on current odor data.
Let’s dive a little deeper.
How supervised learning works
Our goal in detecting odors is to better answer the question, “Is this assertion true?” For example, does a certain raw material have a bad smell? Or did someone smoke in a car? Yes, or no?
In these basic examples, the supervised learning phase consists of first collecting odor signatures during well-known situations, i.e. situations you are able to label with “yes” or “no”. followed by the application of universal mathematical models trained to output the correct answer.
Similar to how a baby might learn how to walk, this process may require many scenarios and large amounts of data for the model to be able to generalize. After the learning phase, when presenting new, unknown situations the model will provide a more relevant response if it was trained with situations not too far off from the real-life use case.
This learning phase may be applied to a variety of typical use cases:
- Detection: Is an odor present or not?
- Classification: What is the odor in the midst of many other odors?
- Regression: Estimation of where the source of the odor is or estimation of the concentration of ingredients in a mixture, or the ripeness level of any goods
Sometimes it’s a combination of all three that enable us to identify a given smell, which can be demonstrated in how digital olfaction works with kitchen appliances. In some cases, performances are improved by adjoining other sensors (TVOC, hygrometer, Thermometer…)
Let’s talk detection
Backing up for a second, let’s dive a little deeper into detection, which is defined as the detection of specific molecules emitted by samples, goods, or individuals. Cigarette smoke in a shared car service, for example. This is an easy example if the odor signal is strong, but for the most part, you’re going to be working with a low signal. That means olfactory measurements of compounds will be more and more diluted, and the odor as a result will be less and less detectable, until a point one commonly admit to be the Limit Of Detection or LOD.
So how can machine learning help to remedy this challenge? As we mentioned in our last blog post, we must compensate for environmental signals and form the difference between a reference (the measurement of ambient air) and the analyte. Let’s say we make several measurements of different flasks with decreasing levels of dilution, and we obtain the output from three bio-sensors – from 0%, which is only made of diluent, to 100%, which is made of the pure compound.
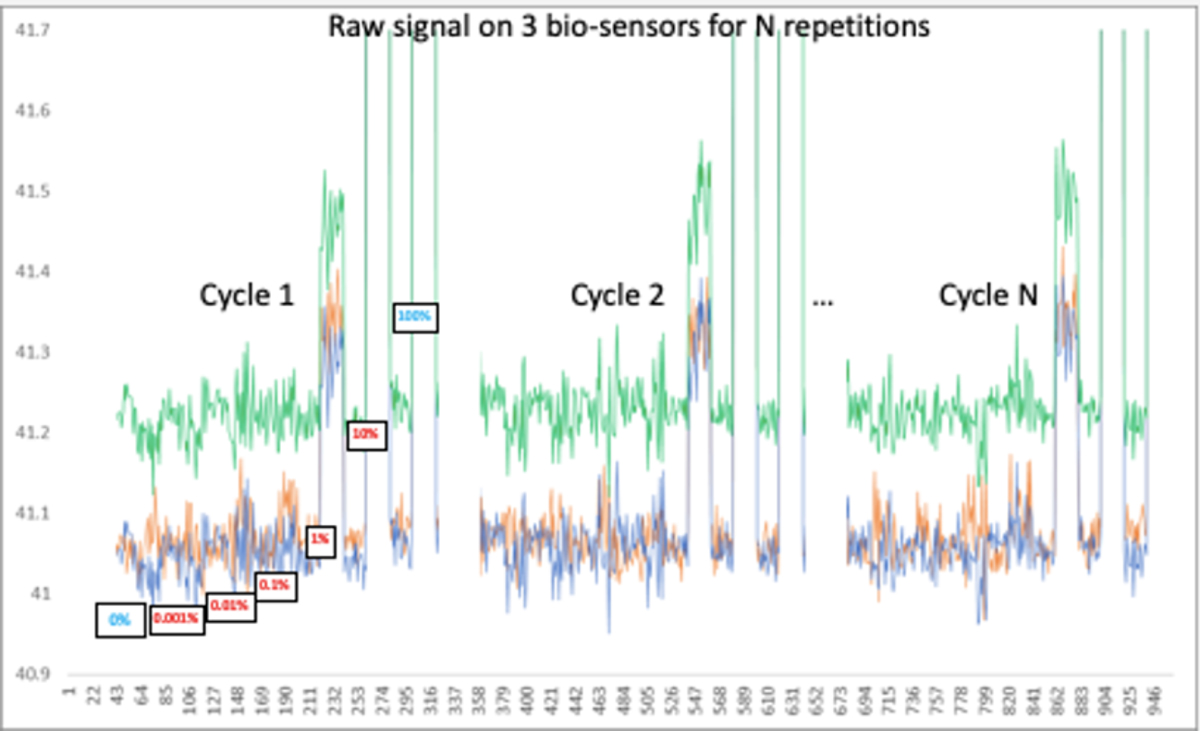 By learning the signature of the records with the pure odor, it’s possible to get a better metric that will separate the different levels of dilution. The goal is to not only look for something different from a pure diluent situation, but to look in the noise for something that is similar to the olfactory compound.
By learning the signature of the records with the pure odor, it’s possible to get a better metric that will separate the different levels of dilution. The goal is to not only look for something different from a pure diluent situation, but to look in the noise for something that is similar to the olfactory compound.
Detection and learning data
Let’s refer to another example – a bad smell left in the cabin of a car, for instance. After a measurement of the indoor atmosphere, the final decision is accepted or rejected. In the latter case, the car may need a cleaning procedure.
To get to that final decision, you can always build a model with learning based on expected responses. This seems simple, but it actually hides all the smelly situations we may encounter in real life. That “rejected” label could include odors of smoke, food, body odor, etc. For the detection to be effective, all these situations in the training phase should be representative of real-life situations, which are collected and stored in a large database. The model will always predict what you have already learned.
How to assess the performance of a classification process
Classification is where an operation automatically decides which category an olfactory record belongs to. For an extreme example, we look to the fragrance market where one would examine a library of floral odors with small nuances not necessarily apparent to the human nose.
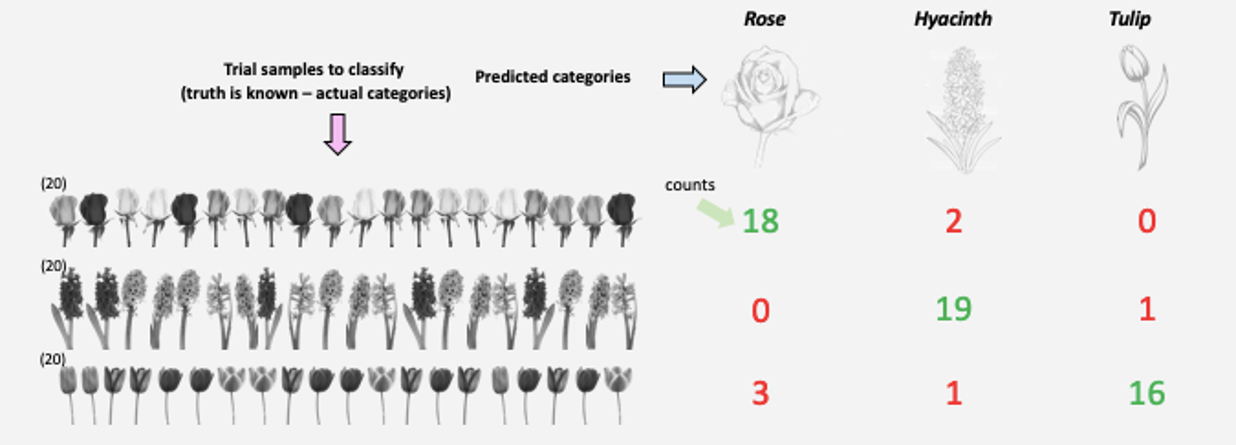
Imagine the model is already learned, and we want to assess the performance of the classifier. To do this, we need to have a database of 20 trials per category whose responses are already annotated with the actual categories. This is just the test data. Each trial flower goes through the model, and we’d count the decisions provided by the classifier for each class.
If the input flowers are sorted as we can see it in this image, the green numbers should be high, and the red numbers should be low.
By learning the signature of the records with the pure odor, it’s possible to get a better metric that will separate the different levels of dilution. The goal is to not only look for something different from a pure diluent situation, but to look in the noise for something that is similar to the olfactory compound.

The benefit of clustering
Lastly, we can’t discuss machine learning without also talking about clustering, which comes from unsupervised learning. Most of the time, clustering is inherent to a model. Before classification, clustering enables you to obtain intermediate results for separating measurements more clearly, so it’s easier to deliver the right classification. The benefit is that this separates the way an odor is detected from cigarette smell as opposed to an air freshener, making it much easier for a sensor in real life to recognize where an odor measurement belongs.
As you can see, machine learning is revolutionizing the way we mimic the human sense of smell by learning directly from odor data and helping us more accurately differentiate between odors. If you’re interested in learning more about how this can help you, contact us.
